
大数据用什么软件,大数据开发与处理的常用软件东西
1. Hadoop:Hadoop 是一个开源结构,答应运用简略的编程模型在大型集群上处理大数据集。它由两个首要部分组成:Hadoop 分布式文件体系(HDFS)和 MapReduce。
2. Spark:Apache Spark 是一个快速、通用且开源的大数据处理引擎。它供给了内存核算才能,适用于批处理、实时处理和机器学习等场景。
3. Flink:Apache Flink 是一个开源流处理结构,用于在无鸿沟和有鸿沟的数据流上进行有状况的核算。它支撑事情驱动运用和实时剖析。
4. Kafka:Apache Kafka 是一个分布式流处理渠道,用于构建实时数据管道和流运用程序。它答应发布和订阅流数据,能够处理高吞吐量的数据。
5. Hive:Apache Hive 是一个构建在 Hadoop 上的数据仓库东西,用于查询和办理存储在 HDFS 中的大数据。它供给了相似于 SQL 的查询言语(HiveQL)。
6. Pig:Apache Pig 是一个依据 Hadoop 的高档数据流渠道,用于处理大数据调集。它供给了一个高档言语(Pig Latin)来简化大数据处理。
7. Cassandra:Apache Cassandra 是一个开源 NoSQL 数据库,适用于处理很多数据,供给高可用性和可扩展性。
8. MongoDB:MongoDB 是一个开源 NoSQL 数据库,运用 JSON 类型的文档来存储数据,适用于灵敏的数据模型和高性能的读写操作。
9. Tableau:Tableau 是一个数据可视化东西,用于将数据转化为直观的图表和仪表板,协助用户发现数据中的洞悉。
10. Power BI:Microsoft Power BI 是一个商业智能东西,用于数据剖析和陈述。它供给了丰厚的可视化选项和强壮的数据衔接才能。
11. D3.js:D3.js 是一个用于运用 Web 规范创立交互式数据可视化的 JavaScript 库。它答运用户创立自定义图表和可视化。
12. TensorFlow:TensorFlow 是一个开源机器学习结构,用于研讨和出产。它供给了强壮的东西和库来构建、练习和布置机器学习模型。
13. PyTorch:PyTorch 是另一个开源机器学习库,专心于灵敏性和动态核算图。它广泛用于研讨和开发机器学习模型。
14. R:R 是一个核算核算和图形言语,广泛用于数据剖析和核算建模。
15. Python:Python 是一种通用编程言语,具有丰厚的数据科学库(如 NumPy、Pandas、Scikitlearn 等),用于数据剖析和机器学习。
这些东西能够依据详细的需求和场景进行挑选和组合运用。在实践运用中,一般需求依据数据的特性、处理需求和剖析方针来挑选适宜的东西。
大数据开发与处理的常用软件东西
跟着大数据年代的到来,企业和安排对海量数据的处理和剖析需求日益增长。为了满意这一需求,市场上出现出了很多大数据软件东西。本文将介绍一些在大数据开发与处理中常用的软件东西,协助读者了解这些东西的特色和运用场景。
一、Hadoop生态体系
1. Hadoop分布式文件体系(HDFS)
HDFS是Hadoop的中心存储体系,它将文件分割成多个数据块,并将这些数据块存储在集群中的不同节点上。HDFS具有高容错性,能够自动检测和康复数据块的丢掉或损坏。它选用主从架构,由一个NameNode和一个或多个DataNode组成。NameNode担任办理文件体系的命名空间、数据块的映射信息以及处理客户端的读写恳求;DataNode则担任实践的数据存储和读写操作。
2. MapReduce
3. YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源办理器,担任集群资源的办理和调度。YARN将资源办理从MapReduce中分离出来,使得Hadoop生态体系能够支撑更多类型的核算结构,如Spark、Flink等。
4. Hive
Hive是一个依据Hadoop的数据仓库东西,它供给了相似SQL的查询方法,适用于批量数据剖析。Hive能够将结构化数据存储在HDFS中,并运用HiveQL进行查询和剖析。
5. HBase
HBase是一个分布式列存储体系,用于存储很多结构化数据。HBase依据Google的Bigtable模型,支撑实时随机读写操作,适用于存储非结构化或半结构化数据。
二、Spark生态体系
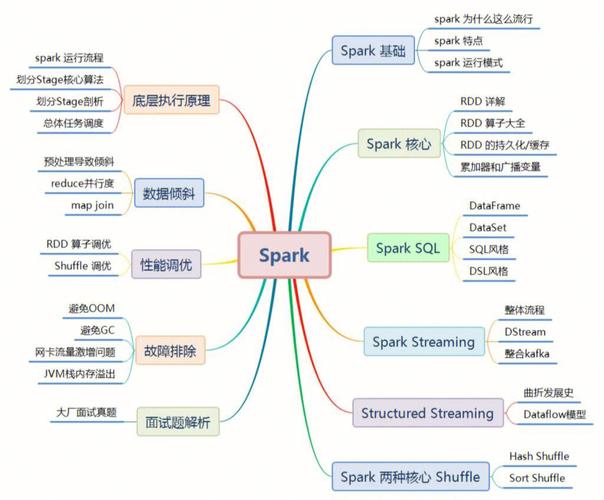
1. Spark Core
Spark Core是Spark的根底结构,供给了内存核算、弹性分布式数据集(RDD)等中心功用。Spark Core能够与Hadoop生态体系无缝集成,并支撑多种数据源。
2. Spark SQL
Spark SQL是Spark的数据处理东西,它供给了相似SQL的查询方法,能够处理结构化数据。Spark SQL能够与Spark Core、Spark Streaming和MLlib等组件无缝集成。
3. Spark Streaming
Spark Streaming是Spark的实时数据处理东西,它能够将实时数据流通换为Spark RDD,并进行实时处理和剖析。
4. MLlib
MLlib是Spark的机器学习库,供给了多种机器学习算法和东西,如分类、回归、聚类、协同过滤等。
5. GraphX
GraphX是Spark的图处理库,它供给了图算法和图剖析东西,能够用于交际网络剖析、引荐体系等场景。
三、其他大数据东西

1. Kafka
Kafka是一个分布式流处理渠道,能够处理大规模数据流。Kafka具有高吞吐量、可扩展性和容错性,适用于实时数据收集、存储和传输。
2. ZooKeeper
ZooKeeper是一个分布式和谐服务,用于保护装备信息、命名空间、同步服务等功用。ZooKeeper在Hadoop生态体系和Spark等大数据东西中扮演着重要人物。
3. Flink
Flink是一个流处理结构,能够处理有界和无界的数据流。Flink具有高吞吐量、低推迟和容错性,适用于实时数据处理和剖析。
4. Elasticsearch
Elasticsearch是一个开源的查找引擎和数据剖析东西,能够用于全文查找、数据剖析、日志剖析等场景。
5. RapidMiner
RapidMiner是一个数据发掘解决方案,供给了丰厚的数据预处理、特征工程、模型练习和评价等功用。
在大数据开发与处理中,挑选适宜的软件东西至关重要。本文介绍了Hadoop生态体系、Spark生态体系以及其他一些常用的大数据东西,期望对读者有所协助。
- 上一篇:数据库功用比照,功用比照
- 下一篇:联合国交易数据库,全球交易信息的宝库
猜你喜欢
 数据库
数据库
oracle关键字,深化解析Oracle数据库中的关键字
1.SELECT用于从表中检索数据。2.FROM指定查询的表。3.WHERE用于设置查询条件。4.GROUPBY用于对成果集进行分组。5.HAVING用于过滤分组后的成果。6.ORDERBY用于对成果...
2025-01-15 0 数据库
数据库
工业大数据渠道,推进制作业转型晋级的要害力气
工业大数据渠道是一个综合性的渠道,旨在经过搜集、存储、处理、剖析和展现很多工业数据,协助企业完成对工业出产中发生的各类数据的搜集、整合和剖析,然后供给决议计划支撑和事务优化的东西。以下是工业大数据渠道的一些要害功用和特色:1.数据搜集与会...
2025-01-15 0 数据库
数据库
大数据规划,引领未来城市开展的才智引擎
大数据规划是一个触及数据搜集、存储、处理、剖析和使用的归纳进程。以下是一个根本的大数据规划结构,包含首要过程和考虑要素:1.清晰方针和需求:确认大数据项目或解决计划的方针和预期效果。辨认事务需求、用户需求和数据需求。2....
2025-01-15 0 数据库
数据库
mysql怎样导入表,MySQL数据库表导入办法详解
MySQL导入表一般有几种办法,以下是几种常见的办法:1.运用MySQL指令行东西:首要,保证你有一个现已存在的数据库。运用`mysql`指令行东西登录到你的MySQL数据库。运用`CREATET...
2025-01-15 0 数据库
数据库
新华社多媒体数据库,威望新闻信息资源的宝库
新华社多媒体数据库是一个综合性的新闻信息服务渠道,汇集了新华社各类新闻信息资源,包括文字、图片、图表、视音频和报刊等。该数据库具有以下特色:1.规划巨大:现在存储了7000多万条文字信息,330多万张新闻图片和图表,以及13000小时的音...
2025-01-15 0 数据库
数据库
大数据跟云核算,交融开展的未来趋势
大数据和云核算是两个密切相关但又不完全相同的概念。大数据(BigData)是指数据规划巨大,传统数据处理运用软件难以捕捉、办理和处理的数据调集。大数据的特点是“4V”,即Volume(数据量大)、Velocity(处理速度快)、Varie...
2025-01-15 0 数据库
数据库
健康大数据剖析,助力精准医疗与健康办理
健康大数据剖析是一个触及多个范畴的杂乱进程,包含但不限于数据搜集、数据存储、数据预处理、数据剖析和数据可视化。以下是对健康大数据剖析的扼要概述:1.数据搜集:健康大数据的来历多种多样,包含医院、诊所、公共卫生机构、健康稳妥公司、可穿戴设备...
2025-01-15 0 数据库
数据库
体系数据库,体系数据库在现代软件开发中的重要性
1.操作体系数据库:在核算机操作体系中,体系数据库或许用于存储体系装备、用户信息、权限设置等数据。这些数据关于体系的正常运转和办理至关重要。2.数据库办理体系(DBMS)数据库:在数据库办理体系中,体系数据库或许指的是用于存储元数据(关...
2025-01-15 0
