
大数据剖析结构,大数据剖析结构概述
1. Hadoop:Hadoop 是一个开源的大数据处理结构,由 Apache 软件基金会保护。它运用 MapReduce 编程模型来处理大规模数据集,并运用 HDFS(Hadoop Distributed File System)来存储数据。
2. Spark:Spark 是一个快速、通用的大数据处理引擎,由 Apache 软件基金会保护。它支撑多种编程言语(如 Scala、Java、Python 等)和多种数据处理场景(如批处理、流处理、机器学习等)。
3. Flink:Flink 是一个开源的流处理结构,由 Apache 软件基金会保护。它支撑事情驱动和实时数据处理,并具有容错性和可扩展性。
4. Hive:Hive 是一个构建在 Hadoop 之上的数据仓库东西,由 Apache 软件基金会保护。它供给了一个相似 SQL 的查询言语(HiveQL)来查询和剖析存储在 HDFS 中的数据。
5. Impala:Impala 是一个开源的、依据内存的 SQL 查询引擎,由 Cloudera 开发。它可以直接在 HDFS 或 HBase 上履行 SQL 查询,并具有低推迟和高功能的特色。
6. Presto:Presto 是一个开源的、分布式的大数据处理结构,由 Facebook 开发。它支撑多种数据源(如 HDFS、Cassandra、MySQL 等)和多种查询言语(如 SQL、JDBC 等)。
7. Druid:Druid 是一个开源的、实时剖析数据存储,由 Metamarkets 开发。它支撑实时数据摄入、快速查询和可扩展性,常用于构建实时剖析运用。
8. Elasticsearch:Elasticsearch 是一个开源的、分布式的查找和剖析引擎,由 Elastic 开发。它支撑全文查找、索引和剖析,并具有高可用性和可扩展性。
9. Kafka:Kafka 是一个开源的、分布式的流处理渠道,由 Apache 软件基金会保护。它支撑高吞吐量、可扩展性和容错性的数据流处理。
10. TensorFlow:TensorFlow 是一个开源的机器学习结构,由 Google 开发。它支撑大规模的机器学习模型练习和推理,并具有可扩展性和灵活性。
这些结构可以依据不同的需求和场景进行挑选和运用,以应对大数据环境下的应战。
大数据剖析结构概述
大数据剖析结构的分类
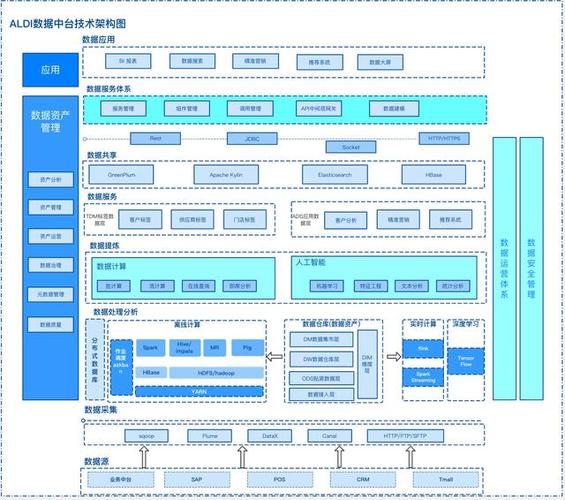
依据不同的运用场景和需求,大数据剖析结构可以分为以下几类:
分布式文件体系:如Hadoop的HDFS、Alluxio等,担任存储海量数据。
分布式核算结构:如Hadoop的MapReduce、Spark、Flink等,担任对数据进行分布式核算。
数据处理和剖析东西:如Hive、Pig、Impala等,供给SQL查询接口,便利用户进行数据处理和剖析。
实时核算结构:如Apache Storm、Apache Flink、Apache Spark Streaming等,担任实时处理和剖析数据流。
机器学习结构:如TensorFlow、PyTorch、Apache Mahout等,供给机器学习算法和模型练习功用。
干流大数据剖析结构介绍
以下介绍几种干流的大数据剖析结构:
Hadoop
Hadoop是一个开源的分布式核算结构,由Apache软件基金会开发。它包含HDFS(分布式文件体系)和MapReduce(分布式核算模型)两个中心组件。Hadoop可以高效地处理和剖析大规模数据集,广泛运用于互联网、金融、医疗、教育等范畴。
Spark
Spark是一个快速、通用的大数据处理引擎,它供给了高档API(如Spark SQL、Spark Streaming、MLlib和GraphX)和用于构建大规模数据处理运用程序的分布式核算模型。Spark在内存中处理数据,比较Hadoop的MapReduce,具有更高的功能和更低的推迟。
Flink
Flink是一个开源的分布式流处理结构,由Apache软件基金会开发。Flink支撑批处理和流处理,具有高功能、低推迟、容错性强等特色。Flink广泛运用于实时数据处理、机器学习、杂乱事情处理等范畴。
Storm
Storm是由Twitter开源的一个分布式实时核算体系,用于处理大规模数据流。Storm具有高吞吐量、低推迟、容错性强等特色,广泛运用于实时数据处理、实时剖析、实时引荐等范畴。
大数据剖析结构的挑选与优化
依据实践需求挑选适宜的结构:不同的结构具有不同的特色和优势,应依据实践需求挑选适宜的结构。
优化数据存储和核算资源:合理装备数据存储和核算资源,进步数据处理和剖析功率。
重视结构的生态圈:挑选具有丰厚生态圈的结构,便利获取相关东西和资源。
重视结构的社区活跃度:挑选社区活跃度高的结构,便于获取技术支撑和解决方案。
大数据剖析结构是支撑大数据剖析的中心技术,关于进步数据处理和剖析功率具有重要意义。了解和把握干流的大数据剖析结构,有助于更好地应对大数据年代的应战。在挑选和优化大数据剖析结构时,应依据实践需求、资源情况和社区活跃度等要素进行归纳考虑。
猜你喜欢
 数据库
数据库
维普中文期刊全文数据库,学术研讨的得力帮手
维普中文期刊全文数据库是一个综合性的学术资源渠道,由维普资讯有限公司推出,首要面向高校图书馆、情报所、科研组织及企业用户。以下是该数据库的具体介绍:简介维普中文期刊全文数据库自1989年推出,依托《中文科技期刊数据库》的数据支撑,录入了国...
2025-01-15 0 数据库
数据库
修建大数据,引领职业革新的新动力
修建大数据在修建职业的运用十分广泛,首要体现在以下几个方面:1.进步职业监管与服务水平:经过大数据剖析,能够完成对全国工程制作企业、注册人员、工程项目的一致会集办理,标准市场主体行为,遏止围标串标等违法现象,保证工程质量,完成质量...
2025-01-15 0- 数据库
mysql怎样读,MySQL 数据读取入门攻略
MySQL是一个开源的联系型数据库办理体系,它运用SQL(结构化查询言语)进行数据查询、更新和办理。以下是关于怎么读取MySQL数据库的一些根本过程:1.装置MySQL:首要,您需求在您的核算机上装置MySQL数据库。您能够...
2025-01-15 0  数据库
数据库
法令法规数据库,法治我国的信息柱石
以下是几个首要的法令法规数据库及其特色,供您参阅:1.国家法令法规数据库:特色:由全国人大常委会法制作业委员会建造,供给宪法、法令、行政法规、督查法规、司法解说、地方性法规等法令法规的全文和修正、废止的决议。最新法令法规速...
2025-01-15 0 数据库
数据库
大数据剖析软件,助力企业智能化转型
1.Hadoop:Hadoop是一个开源结构,用于在大型集群上存储和处理大数据。它由ApacheSoftwareFoundation开发,是大数据剖析范畴的事实标准之一。2.Spark:Spark是一个快速、通用的大数据处理...
2025-01-15 0 数据库
数据库
mirbase数据库,miRNA研讨的得力助手
Mirbase数据库是一个由曼彻斯特大学的研讨人员开发的在线miRNA数据库(序列数据库),主要功用包含存储miRNA的序列数据、注释信息和猜测基因靶标等。它是现在最全面的miRNA数据库之一,收录了来自200多个物种,挨近4万个miRNA...
2025-01-15 0 数据库
数据库
pubchem数据库,化学信息资源的宝库
PubChem数据库是一个由美国国家生物技术信息中心(NCBI)保护的敞开化学数据库,首要支撑有机小分子生物活性数据。以下是关于PubChem数据库的具体介绍:1.数据库概述PubChem数据库由美国国立卫生研讨院(NIH)支撑,是一个...
2025-01-15 0 数据库
数据库
图书馆大数据剖析体系,助力才智图书馆建造
1.体系功用:数据整合与剖析:体系能够全面整合图书馆的各类数据,包含借阅记载、访客行为、藏书流转等,并进行智能剖析,提醒借阅行为规则,优化运营功率。可视化展现:经过动态数据图表等方法,以直观的方法展现图书馆的全体事务、要害...
2025-01-15 0
